NFTruth
NFTruth is an intelligent system that analyzes NFT collections to determine their legitimacy and detect potential scams. Using ensemble machine learning algorithms trained on multi-source data (OpenSea marketplace data, Reddit social sentiment, and Ethereum blockchain metrics), it provides comprehensive risk assessments for NFT collections.
🎯 Project Goals
Fighting NFT scams with machine learning, one collection at a time! This system functions as a research tool to demonstrate how advanced ML techniques can be applied to blockchain analysis for scam detection.
🧠 How The System Works
📊 Multi-Source Data Collection Pipeline
- OpenSea API Integration: Extracts comprehensive collection metrics including verification status, volume, floor price, ownership stats, and more.
- Reddit Social Intelligence: Uses OAuth 2.0 to access reddit data for sentiment analysis (VADER), detecting “hype” phrases vs. “scam” keywords across crypto communities.
- Blockchain Analysis: Framework for analyzing creator wallet age, transaction history, and suspicious patterns like wash trading.
🔬 Advanced Feature Engineering
Raw data is transformed into 20+ meaningful ML features, falling into three categories:
- Market Intelligence: Liquidity quality, market efficiency, price premiums, and volume metrics.
- Social Sentiment Scoring: Community engagement, sentiment polarity, and scam keyword density.
- Blockchain Forensics: Creator wallet age, wash trading scores, and mint distribution uniformity.
🤖 Ensemble Machine Learning Architecture
The heart of NFTruth is an ensemble of four specialized algorithms:
| Model | Strengths | Use Case |
|---|---|---|
| Logistic Regression | Interpretable, fast | Primary classifier (most optimal) |
| Random Forest | Feature importance | Complex interaction detection |
| Gradient Boosting | Sequential learning | Subtle scam pattern recognition |
| SVM | High-dimensional separation | Precise decision boundaries |
🏷️ Intelligent Labeling System
Since ground truth is rare, the system uses a sophisticated scoring methodology to create synthetic labels based on verification signals, social presence, and market consistency.
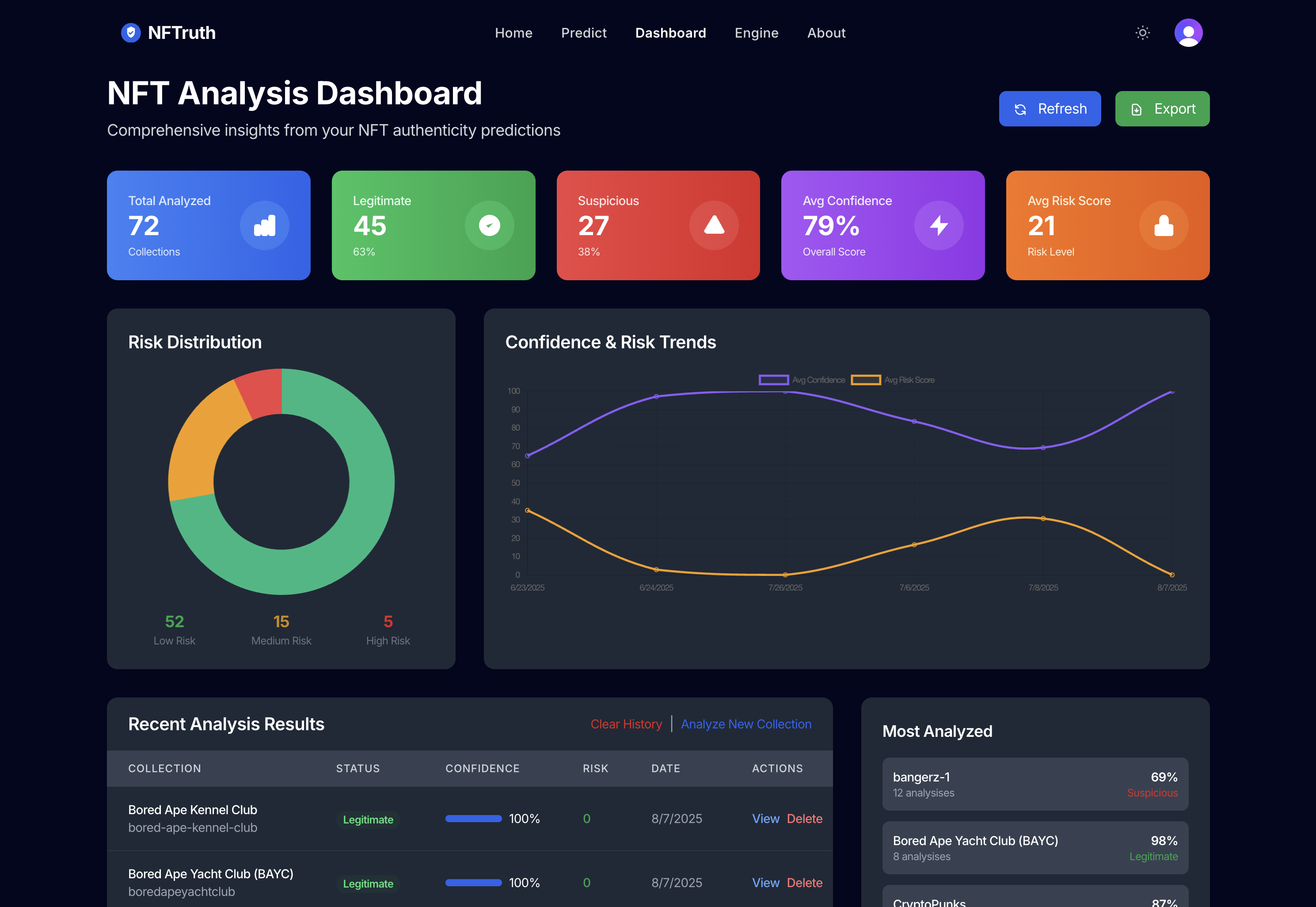
⚠️ Risk Classification System
The system outputs a risk probability which is categorized as:
- 🟢 Low Risk (0-30%): Verified, high volume, strong community.
- 🟡 Medium Risk (31-50%): Mixed signals, some concerns.
- 🟠 High Risk (51-70%): Multiple red flags detected.
- 🔴 Very High Risk (71-100%): Strong scam indicators.
🛠️ Technology Stack
- Logic: Python
- ML & Data: Scikit-learn, Pandas, NumPy
- NLP: NLTK, VaderSentiment
- APIs: OpenSea, Reddit, Etherscan
- Visualization: Matplotlib, Seaborn
📂 System Architecture
NFTruth/
├── 🎯 app/
│ ├── 📊 data/
│ │ ├── opensea_collector.py # OpenSea API integration
│ │ ├── reddit_collector.py # Reddit OAuth + sentiment pipeline
│ │ └── ml_data_transformer.py # Feature engineering
│ ├── 🤖 models/
│ │ ├── model.py # Ensemble ML model implementation
│ │ └── opensea_known_legit.py # Curated legitimate collections
│ ├── 📈 model_training.py # Training pipeline
│ └── 🔮 predict.py # Prediction interface
├── 🏆 model_outputs/ # Saved models
└── 📚 training_data/ # Generated datasets